AI Gateway 란?
여러 인공지능 모델이나 서비스들을 하나의 통합된 출입구 (게이트웨이)로 묶어 관리하고 사용할 수 있게 해주는 중간 계층 시스템입니다.
즉, 모든 애플리케이션이 직접 LLM(API)으로 가는 것이 아닌, AI Gateway를 통해 통합적으로 접근을 하게 해주는 역할을 합니다.
AI Gateway 왜 필요한가?
요즘 수 많은 AI API 공급자들이 많이 있고, 해당 공급자들 안에서도 다양한 AI 모델이 존재합니다.
이러다보니 문제가 발생합니다.
AI 모델이 많아질수록 API 관리가 복잡해지고, 비용 예측이 어려워져 서비스 운영의 효율이 떨어지게 됩니다.
이런 문제를 해결하기 위해 AI Gateway 가 필요해졌고 주요 기능은 아래와 같습니다.
| 주요 기능 | 설명 | 비유/예시 |
|---|---|---|
| 인증 및 접근 제어 (Auth & Access Control) | 어떤 사용자나 애플리케이션이 어떤 모델에 접근할 수 있는지 제어 | 예: “A팀은 사내 GPT만 사용 가능”, “B팀은 OpenAI API 접근 가능” |
| 요청 라우팅 및 모델 선택 (Request Routing) | 요청을 분석해 적합한 모델이나 엔드포인트로 전달 | 예: “분류 요청은 BERT로, 생성 요청은 GPT로 보내기” |
| 비용 및 사용량 관리 (Cost & Usage Control) | 모델별 사용량, 토큰 수, 호출 횟수 등을 모니터링하고 비용을 통제 | 예: “팀별 AI 사용량 대시보드 생성” |
| 프롬프트 관리 (Prompt Management) | 표준화된 템플릿, 금칙어 필터링, 프롬프트 로깅 등 | 예: “비속어나 개인정보 포함 프롬프트는 차단” |
| 로깅·모니터링·감사 (Observability & Audit) | 모든 AI 요청/응답을 기록하여 모니터링 및 규제 대응 | 예: “A사가 어떤 답변을 냈는지 추적 가능” |
| 보안 및 데이터 보호 (Security) | 입력/출력 데이터 필터링, 마스킹, 암호화 등 수행 | 예: “민감 정보(주민번호, 이메일 등) 자동 마스킹” |
| 모델 추상화 (Model Abstraction) | 여러 모델(OpenAI, Anthropic, 사내 모델 등)을 통합 인터페이스로 제공 | 예: “/api/generate 하나로 여러 LLM 호출 가능” |
| 후처리 및 품질관리 (Post-processing & Validation) | 모델 응답을 필터링하거나 포맷 정돈, 신뢰도 평가 | 예: “응답에 금지된 단어가 있으면 다시 생성” |
이러한 기능이 존재하는 툴을 찾다 보니 Apache APISIX 라는 오픈소스 툴을 알게 되었습니다.
Apache APISIX 란?
Apache APISIX는 클라우드 네이티브 API Gateway로,
트래픽 관리, 인증, 로드 밸런싱, 관찰성(Observability) 등
API 요청 전반을 제어·보호·최적화할 수 있게 해주는 오픈소스 플랫폼 입니다.
APISIX의 구조

이미지 출처: https://apisix.apache.org/docs/apisix/architecture-design/apisix/
위 아키텍처 이미지를 보면 APISIX는 Nginx 와 Ngx_lua 기반으로 LuaJIT 기능을 활용하여 구성되었습니다.
각 계층을 살펴보면 아래와 같습니다.
- Nginx
- OpenResty
- Apisix Core
- Plugine Runtime
- Built-in-Plugins Nginx Layer - 네트워크 입구 (Gateway의 기반 엔진)
- 가장 하단 계층으로, 실제 HTTP/TCP 요청을 수신하고 응답을 처리하는 역할 담당
- NGINX를 그대로 사용
OpenResty Layer - Nginx를 확장하는 런타임
- OpenResty는 Nginx 위에 LuaJIT(Lua Just-In-Time compiler)를 얹어서 “동적으로 코드를 실행할 수 있는 Nginx 런타임 환경” 을 제공합니다.
- 쉽게 말해, nginx.conf로 nginx을 동작하는 것이 아닌, Lua 코드로 제어되게 할 수 있습니다.
Apisix Core Layer - 게이트웨이의 핵심 로직
- OpenResty 위에서 동작하는 Apisix의 코어 엔진 입니다.
- 라우팅 엔진: URL, Host, Header, Method 등 다양한 조건으로 트래픽 라우팅
- 로드 밸런싱: round-robin, hash, least_conn 등 알고리즘 지원
- Upstream 헬스체크: Gateway를 거쳐서 도달할 애플리케이션의 상태를 주기적으로 검사
- Service Discovery: Kubernetes, Consul, Nacos, DNS 등 외부 서비스 레지스트리와 통합
Apisix Plugin Runtime - 확장 가능한 동적 플러그인 계층
- 여기서 모든 정책 / 인증 / 로깅/ 트래픽 제어 / Rate Limit 등이 동작
- 내장 플러그인은 Lua 스크립트로 작성을 합니다.
Multi-language Plugin Runtime - 언어 확장성
- 다양한 언어(Java, Go, Python 등) 다양한 언어로 플러그인을 실행할 수 있습니다.
- 즉, Lua로 작성하지 않아도 gRPC 기반으로 외부 프로세스에서 플러그인 실행 가능
즉, 정리를 하자면 Apisix는 두 가지 주요 부분으로 구성됩니다.
- Apisix 코어, Lua 플러그인, 다양한 개발언어 플러그인 런타임, WASM 플러그인 런타임
- 관찰성, 보안, 트래픽 제어 등의 기능을 추가하는 내장 플러그인
주요 구성 요소들에 대해 더 자세히 알아보자면, 아래의 표와 같습니다.
| 구성 요소 | 설명 |
|---|---|
| APISIX Core | 요청 라우팅, 로드 밸런싱, 서비스 디스커버리, 설정 관리, 관리용 API 를 담당 |
| Plugin Runtime | 플러그인을 실행하는 환경으로, Lua / 멀티언어 런타임 / WASM 런타임을 포함 |
| Built-in Plugins | 인증, 보안, 관찰성, 트래픽 제어 등의 기능을 제공하는 내장 플러그인 (Lua로 작성) |
APISIX의 데이터 동기화 구조

이미지 출처: https://api7.ai/ko/blog/apache-apisix-3-0-11-highlights-of-open-source-api-gateway
| 구분 | Control Plane (제어 플레인) | Data Plane (데이터 플레인) |
|---|---|---|
| 핵심 역할 | 설정을 저장하고 배포 | 트래픽을 처리하고 실행 |
| 주요 책임 | • 라우트, 업스트림, 플러그인 등록/변경·설정을 etcd에 저장 • etcd를 통해 데이터 플레인에 전달 |
• 클라이언트 요청 수신 • etcd에서 설정을 가져와 라우팅·플러그인 실행 (Auth, Rate Limit 등) |
| 상태(state) | 설정(stateful: etcd 저장) | 무상태(stateless) – 필요하면 얼마든지 늘려도 됨 |
| 구성 요소 | Admin API + etcd (+ 옵션: Ingress Controller) | APISIX Gateway Pods |
| 통신 방향 | Admin API → etcd → APISIX Pods | APISIX Pods ↔ etcd (watch) |
| 예시 리소스(EKS) | apisix-etcd-, (옵션) apisix-ingress-controller- | apisix-* (게이트웨이 파드들) |
| 장애 영향 | 꺼져도 기존 설정은 유지, 새 설정 등록은 불가 | 꺼지면 트래픽 중단 (요청 처리 불가) |
Control Plane(etcd) ↔︎ Data Plane(api-gateway) 관계의 핵심은 “etcd Watch” 입니다.
Apisix는 설정을 etcd에 저장을 합니다.
Control Plane은 etcd에 Write(쓰기)를, Data Plane은 etcd를 Watch(구독) 합니다.

요청 처리 프로세스
먼저 다이어그램을 살펴보면 아래와 같습니다.
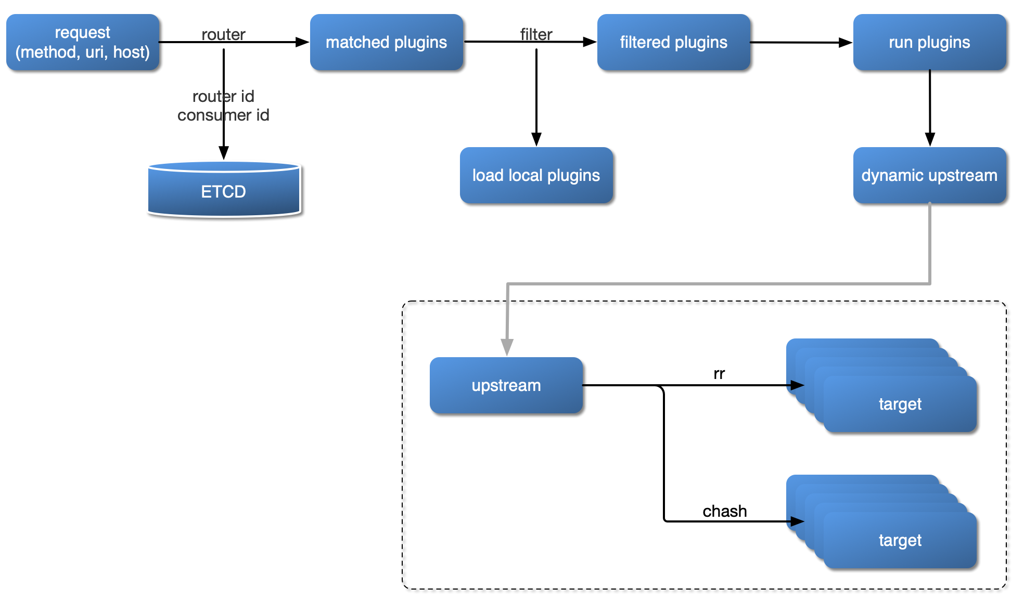
이미지 출처: https://apisix.apache.org/docs/apisix/architecture-design/apisix/
- 클라이언트 요청이 들어오면
- 요청에 맞는 플러그인에 매치되도록 라우팅 (해당 과정에서 라우팅 id와 consumer id가 ETCD에 저장됩니다.)
- 라우트가 결정된 뒤 어떤 플러그인을 실행 시킬 지 필터 후 플러그인 실행
- 플러그인 실행한 후, Apisix가 요청을 최종 목적지(Upstream, AI agent 파드 or API 파드)로 보냅니다.
플러그인 계층 구조
아래 다이어그램은 다양한 유형의 플러그인에 요청이 들어왔을 때 어떻게 동작을 하는지 보여줍니다.
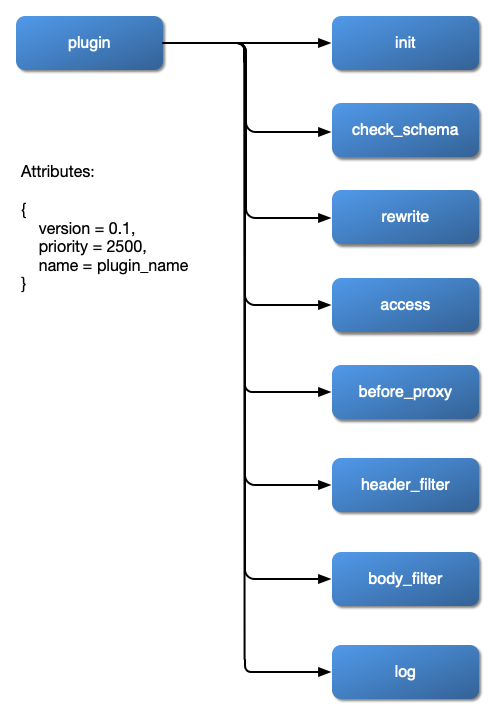
이미지 출처: https://apisix.apache.org/docs/apisix/architecture-design/apisix/
이 다이어그램은 Apisix 플러그인의 생명주기(lifecycle)
즉, 요청이 들어와서 응답이 나가기까지 플러그인이 실행되는 순서와 역할을 보여주는 핵심 구조도 입니다.
| 순서 | Phase 이름 | 실행 시점 | 주요 역할 |
|---|---|---|---|
| ① init | 초기화 단계 | APISIX 시작 시 또는 플러그인 로드 시 1회 실행 | 전역 설정, 캐시 초기화 등 |
| ② check_schema | 설정 검증 단계 | 플러그인 설정이 등록되거나 변경될 때 | 플러그인 설정값 (JSON/YAML)의 스키마 유효성 검사 |
| ③ rewrite | 요청 재작성 단계 | 요청이 라우팅된 후, 백엔드로 전달되기 전 | 요청 URI, 헤더, 쿼리 파라미터 변환 등 |
| ④ access | 접근 제어 단계 | 백엔드 호출 전 (핵심 phase) | 인증/인가, 속도 제한, 로깅 등 핵심 로직 수행 |
| ⑤ before_proxy | 프록시 전 직전 단계 | 백엔드로 요청 보내기 직전 | 커넥션 재설정, 헤더 추가, 최종 변경 등 |
| ⑥ header_filter | 응답 헤더 필터 단계 | 백엔드 응답 헤더 수신 시 | CORS 헤더 추가, 보안 헤더 수정 등 |
| ⑦ body_filter | 응답 바디 필터 단계 | 응답 바디 스트림 처리 시 | 바디 압축/치환, 데이터 마스킹 등 |
| ⑧ log | 로깅 단계 | 요청/응답 완료 후 | Access 로그, Metrics, Tracing 등 전송 |
이번 글은 여기까지 입니다.
다음 글에서는 실제로 APISIX 설치하고 커스텀 플러그인 어떻게 만들어서 사용 해보았는지 알아보겠습니다.
감사합니다.
'네트워크 > APISIX' 카테고리의 다른 글
| AI 트래픽을 관리하는 방법: APISIX로 AI Gateway 만들기 - 2편 (설치 및 Custom Plugin 개발) (0) | 2025.11.03 |
|---|