카프카는 브로커 한두 대에서 장애가 발생하더라도 중앙 데이터 허브로서 안정적인 서비스가 운영될 수 있도록 구상되었습니다.
이 때 안정성 확보를 위해 카프카 내부에서는 리플리케이션 이라는 동작을 하게 됩니다.
리플리케이션 동작 개요
카프카에서 데이터는 토픽(topic) → 파티션(partition) 단위로 저장됩니다.
각 파티션은 하나의 리더(Leader)와 여러 개의 팔로워(Follower) 복제본으로 구성됩니다.
리더(Leader)
: 실제로 프로듀서와 컨슈머가 읽고 쓰는 주체팔로워(Follower)
: 리더의 데이터를 동기화(Replication) 하는 복제본, 리더가 장애나면 팔로워 중 하나가 리더로 승격 하게 됩니다.
리더와 팔로워가 하는 역할에 대해 좀 더 자세히 알아보면,
카프카는 모두 동일한 리플리케이션들을 리더와 팔로워로 구분하고, 각자 역할을 분담시킵니다.
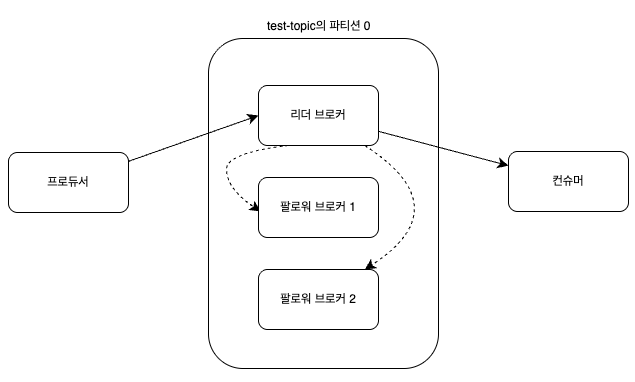
이 그림을 보면 프로듀서가 팔로워 브로커가 아닌 리더 브로커한테만 메시지를 보냅니다.
그 이후 리더 브로커가 팔로워 브로커들에게 메세지를 나눠줍니다.
여기서, 리플리케이션은 리더 파티션의 데이터를 여러 팔로워 파티션에 동일하게 복제하여 장애 시에도 데이터 손실 없이 서비스가 지속되도록 하는 동작 입니다.
이제 리더와 팔로워 간에 어떻게 복제 동작이 이루어지는지에 대해 알아보겠습니다.
리플리케이션의 동작 과정
리더와 팔로워는 ISR(In Sync Replica) 라는 논리적 그룹으로 묶여 있습니다.
이렇게 논리적 그룹으로 묶어둔 가장 큰 이유는 리더가 사라졋을 경우 팔로워들 중 새로운 리더로 선출되는 자격을 가질 수 있기 때문 입니다.
ISR 그룹에 속하지 못한 팔로워는 새로운 리더 자격을 가질 수 없습니다.
따라서, ISR 내의 팔로워들은 리더와 데이터 일치를 유지하기 위해 지속적으로 리더의 데이터를 따라가게 되고, 리더는 ISR 내 모든 팔로워가 메시지를 받을 때까지 기다립니다.
다만, 네트워크 오류나, 브로커 장애로 인해 팔로워가 리더와 동일한 데이터를 가지고 있지 않은 상태에서 리더로 승격이 되면 정합성에 큰 문제가 생깁니다.
그렇다면 리더와 팔로워 중 리플리케이션 동작을 잘하고 있는지 여부 등은 누가 판단하고 어떤 기준으로 판단 하는지 알아보겠습니다.
리더 앞서 이야기 했던 것처럼 읽기/쓰기 동작 뿐 아니라 팔로워가 리플리케이션 동작을 잘 수행하고 있는지도 판단 합니다.
팔로워가 리플리케이션 동작을 제대로 수행하지 못하고 있으면 ISR 그룹에서 추방을 시켜야 하기 때문 이죠.
그렇다면, ISR 그룹 내에서 리더와 팔로워의 단계별 리플리케이션 동작을 그림과 함께 알아보겠습니다.
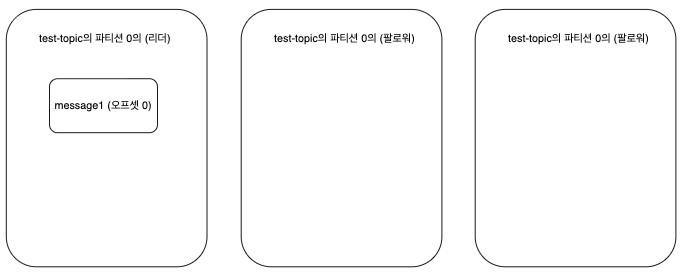
우선 초기에 프로듀서가 메시지를 보내면 리더 브로커만 가지고 있습니다.
이후, 팔로워 브로커들이 리더 브로커에게 0번 오프셋 메시지 가져오기 (fetch) 요청을 보내면,
팔로워 브로커들도 리더 브로커로부터 message1 메시지를 리플리케이션 하게 됩니다.

다만, message1 메시지가 팔로워 브로커에 리플리케이션이 되어도 리더 브로커는 팔로워 브로커가 제대로 메시지를 가져갔는지에 대한 여부를 모릅니다.
전통적인 메시징 큐 시스템인 래빗MQ 의 트랜잭션 모드에서는 메시지를 받았는지에 대한 ACK를 리더에게 리턴하므로 리더가 메시지를 받았는지를 알 수 있습니다.
그러나, 카프카의 경우에는 리더와 팔로우 사이에 ACK를 주고 받는 통신이 없습니다.
오히려 리더와 팔로우 사이에 ACK 통신을 제거함으로써 리플리케이션 동작의 성능을 높였습니다.
그렇다면 어떻게 리더 브로커 입장에서 팔로우 브로커가 제대로 메시지를 가져갔는지 확인을 하냐면,
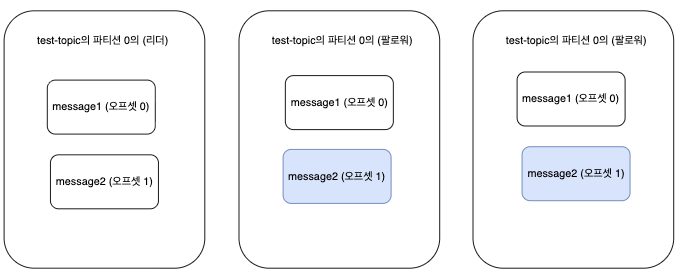
프로듀서가 리더 브로커에게 새로운 메시지인 message2 를 넣어주면, 팔로워 브로커는 리더 브로커를 바라보다가
자신들에게도 메시지를 달라고 요청을 보냅니다.
이 때, 이전 메시지인 message1을 제대로 저장하지 못한 팔로워는 리더 브로커에게 새로운 메시지 요청을 보내지 못합니다.
따라서 리더는 팔로워가 새로운 메시지 요청을 보내면 해당 팔로워 브로커는 오프셋0 에 있던 이전메시지(message1)를 팔로워가 제대로 저장을 했다는 사실을 알게됩니다.
그 후 오프셋 0에 대해 커밋 표시를 한 후 하이워터마크를 증가시킵니다.
그리고 팔로워들이 모두 오프셋 0 에 있던 메시지를 정상적으로 받은 사실을 확인하면 message1를 커밋하게 됩니다.
이후 오프셋1 에 있는 message2를 팔로워들에게 나누어 주면서 message1을 커밋한 사실에 대해서도 알려줍니다.
그렇게되면 팔로워들도 리더와 동일하게 message1을 커밋하고 message2를 받게 됩니다.
이렇게 리더와 팔로워가 어떻게 리플리케이션을 하는지 자세하게 알아봣습니다.
카프카는 여타 메시징 시스템들과 다르게 ACK 통신을 하지 않고 리플리케이션 동작 방식을 팔로워가 Pull 하는 방식을 선택하므로 리더의 부하를 줄여주었습니다.
이제 실제로 토픽을 생성해보면서, 리플리케이션 동작을 시켜주기 위해 토픽을 생성할 때 어떤 설정을 넣어주어야 하는지 알아보겠습니다.
실습
카프카의 리플리케이션 동작을 위해 토픽 생성 시, 필수값으로 replication factor 라는 옵션을 설정 해야합니다.
우선 토픽을 생성해보도록 하겠습니다.
저 같은 경우는 실습을 EKS에서 Strimzi kafka 위에서 해보았습니다.
- 토픽 생성
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: test-topic # Kubernetes 리소스 이름 (unique)
labels:
strimzi.io/cluster: kafka-cluster # 이 토픽이 속한 Kafka 클러스터 지정 (필수)
spec:
topicName: test-1-topic # 실제 Kafka 내부의 토픽 이름
partitions: 3 # 파티션 수 (기본값 없음, 반드시 지정)
replicas: 1 # Replication factor 개수 (기본값 없음, 반드시 지정 그리고 브로커의 개수 이상으로 지정할 수 없습니다.)
config: # 토픽 구성 설정 (Kafka의 topic-level 설정 반영 가능)
# 각 파티션별 segment 파일 최대 크기, 현재 값은 1GB
segment.bytes: 1073741824
# 메시지 보존 기간 (7일)
retention.ms: 604800000
# 메시지 최대 크기 (1MB)
max.message.bytes: 1048576위 YAML 파일에서 알아보려 했던 부분은, replicas 입니다.
해당 부분의 설정이 리플리케이션이 동작할 수 있도록 리더와 팔로워 브로커의 개수를 지정해주는 설정 입니다.
replicas를 1로 설정을 해서 토픽을 생성하면 리더 브로커만 지정을 해주는 것이고,
replicas를 2로 설정을 하면 리더 브로커 1개, 팔로워 브로커 1개를 지정을 해주는 것 입니다.
중요한 점은
- replicas의 개수를 총 브로커 개수 이상으로 지정할 수 없고
- RF(Replication Factor)의 개수를 나중에 수정하기가 어렵다는 점 입니다.
토픽을 생성하고 Apache Kafka UI에서 토픽에 대한 정보를 확인해보면 아래의 이미지와 같습니다.

replicas에서 1로 설정해주면 Replication Factor가 1로 설정되는 것을 확인 할 수 있습니다.
또한 각 파티션에서 보면 Replicas에 브로커가 1개씩만 존재하는 것을 볼 수 있습니다.
이상 입니다.
감사합니다.
'Kafka' 카테고리의 다른 글
| Strimzi Kafka mTLS 적용 알아보기 (0) | 2025.12.03 |
|---|---|
| AWS MSK 메트릭 수집 및 모니터링 (0) | 2025.11.06 |
| 카프카 프로듀서 구조와 동작 원리 (0) | 2025.10.24 |
| Kafka는 왜 이렇게 빠르고 안정적일까? — 높은 처리량과 안정성을 만드는 핵심 원리 (0) | 2025.10.24 |
| Kafka 저장 구조의 모든 것: Partition, Replication, Segment (0) | 2025.10.24 |