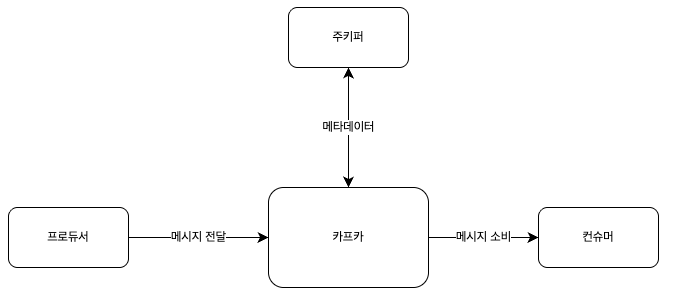
카프카는 데이터를 받아서 전달하는 데이터 버스의 역할을 합니다.
카프카에서 데이터(메시지)를 만들어서 주느 쪽을 프로듀서(Producer),
데이터(메시지)를 소비하는 쪽을 컨슈머(Consumer) 라고 합니다.
그리고 주키퍼는 카프카의 정상 동작을 보장하기 위해 메타데이터(metadata)를 관리하는 코디네이터라 할 수 있습니다.
리플리케이션
리플리케이션(replication)이란?
각 메시지들을 여러 개로 복제해서 카프카 클러스터 내 브로커들에 분산시키는 동작을 의미합니다.
이러한 동작 덕분에 브로커 한개가 종료되더라도 다른 브로커가 살아있다면 카프카는 안정성을 유지할 수 있습니다.
실제 동작을 보면, 카프카에서 토픽이 리플리케이션이 되는 것이 아닌, 토픽의 파티션이 리플리케이션이 됩니다.
그래서, 리플리케이션 팩터 수가 커지면 안정성은 높아지지만, 그 만큼 브로커 리소스를 많이 사용하게 되어, 불필요한 리소스 오버헤드가 발생하지 않도록 잘 설정해주어야 합니다.
- 명령어
kafka-topics.sh --bootstrap-server <부트스트랩서버>:9092 --create --topic <원하는 토픽 이름> --partitios <원하는 파티션 개수> --replication-factor <원하는 리플리케이션 개수>
옵션 설명
--replication-factor: 3
=> 카프카 내 3개의 리플리케이션을 유지하겠다는 의미주의 사항으로는 리플리케이션 개수가 브로커 개수보다 많으면 안됨
✅ 내용을 요약해보자면,
리플리케이션 팩터(replication factor) 는
👉 “한 파티션이 전체 몇 개의 복제본(replica) 을 가질지를 의미”합니다.
즉,
리더(Leader) 브로커 + 팔로워(Follower) 브로커 의 총합 개수예요.
파티션
파티션(partition)이란?
하나의 토픽이 한 번에 처리할 수 있는 한계를 높이기 위해 토픽 하나를 여러 개로 나눠 병렬 처리가 가능하게 만든 것을 파티션 (partition) 이라고 합니다.
하나의 토픽에 여러 개의 파티션으로 나누어 놓으면 파티션 수 만큼 컨슈머를 연결 할 수 있어서,
파티션 개수는 성능, 확장성, 병렬성, 리소스 사용량에 직결되는 핵심 요소 입니다.
그림으로 예시를 들어보면 아래와 같습니다.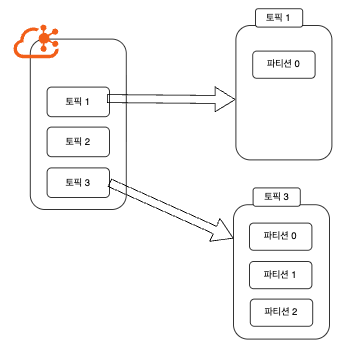
보다 시피 하나의 토픽에 파티션 개수가 여러 개 생성이 될 수 있고 컨슈머가 파티션 개수 만큼 붙어서 병렬 쓰기/읽기가 가능해져 TPS가 올라갈 수 있습니다.
또한, 파티션 수는 초기 생성 후, 언제든지 늘릴 수 있지만, 반대로 줄이는 것은 불가능 하다는 점을 꼭 인지하셔야 합니다.
다만 주의 사항으로는, 파티션의 개수를 과도하게 늘렸을 경우, 리밸런싱의 시간이 길어지고 그 만큼 서비스 지연이 발생할 수 있습니다.
따라서 파티션 수를 늘릴 때는 메시지 처리량이나, 컨슈머의 LAG 등을 모니터링 하면서 조금씩 늘려가는 방법이 좋습니다.
세그먼트
세그먼트란?
하나의 파티션을 여러 개의 작은 로그 파일로 쪼갠 단위 입니다.
이해하기 쉽게 그림과 같이 설명을 해보자면,
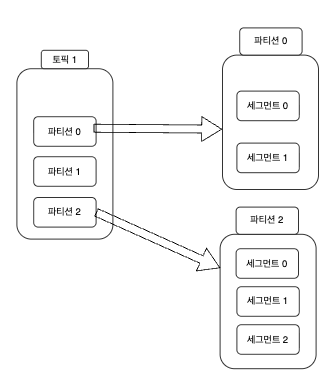
프로듀서가 보낸 메시지는 토픽의 파티션 안에 저장이 됩니다.
그리고 각 메시지들은 세그먼트 (segment) 라는 로그 파일의 형태로 브로커의 로컬 디스크에 저장이 됩니다.
그래서 파티션과 세그먼트의 관계가 나온 그림이 바로 위 그림 입니다.
그리고 실제로 브로커 안에 들어가서 세그먼트를 살펴보면 토픽의 파티션 안에 로그 파일로서 존재하는 것을 확인할 수 있습니다.
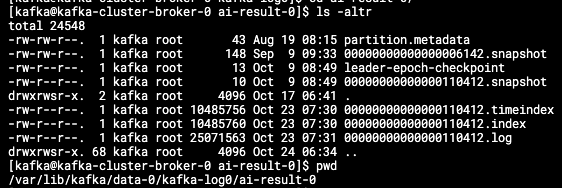
이상 입니다.
'Kafka' 카테고리의 다른 글
| 카프카 프로듀서 구조와 동작 원리 (0) | 2025.10.24 |
|---|---|
| Kafka는 왜 이렇게 빠르고 안정적일까? — 높은 처리량과 안정성을 만드는 핵심 원리 (0) | 2025.10.24 |
| Strimzi Kafka 설치 (1) | 2025.08.13 |
| Strimzi kafka 란? (2) | 2025.08.11 |
| Apache Kafka 에 대해 알아보기 (2) | 2025.08.06 |