인터넷에 카프카를 검색해보면,
- 높은 처리량
- 빠른 응답 속도
- 안정성
위와 같은 특징을 가진 분산형 스트리밍 플랫폼 이라는 설명을 보셧을 겁니다.
이번 글에서는 왜 카프카가 높은 처리량과 안정성을 지니게 되었는지 보도록 하겠습니다.
카프카의 고성능과 안정성을 만드는 핵심 기술들
이제부터 설명드리는 내용을 종합해보면, 왜 카프카가 높은 처리량과 안정성을 지니게 되었는지 어느정도 감이 오실 겁니다.
분산 시스템
분산 시스템은 네트워크상에서 연결된 서버들의 그룹을 말하며, 단일 시스템이 갖지 못한 높은 성능을 목표로 합니다.
또한 성능이 높은 것 뿐 아니라 특정 서버에서 장애가 발생했을 때, 그룹 내 다른 서버가 장애가 발생한 서버 대신 처리를 해줄 수 있으므로 장애 대응도 탁월 합니다.
이러한 내용을 말한 이유는, 카프카 역시도 분산 시스템으로 구성되어 클러스터의 리소스가 한계치에 도달한 경우 브로커의 개수를 수평으로 확장하는 방식으로 해결 할 수 있습니다.
페이지 캐시
카프카는 높은 처리량을 얻기 위해 몇 가지 기능을 추가했는데, 그 중 대표적인 것이 페이지 캐시 입니다.
페이지 캐시란
직접 디스크에 읽고 쓰는 대신 물리 메모리 중 애플리케이션이 사용하지 않는 일부 잔여 메모리를 활용하여 디스크 I/O에 대한 접근을 줄여 성능을 높일 수 있습니다.
배치 전송 처리
카프카는 프로듀서가 메시지를 일정량 모아서 한번에 브로커로 보내는 동작을 합니다.
이러한 동작을 배치 전송 처리 라고 합니다.
이렇게 하는 이유는 간단하게 말해, 실시간 처리보다 효율적이여서 입니다.
실시간으로 단일 메시지 단위로 전송을 하면 네트워크 I/O 요청이 많아서 동작이 느려질 위험이 있기 때문입니다.
압축 전송
카프카는 메시지 압축 전송 기능을 지원 합니다.
가장 큰 이유는, 카프카에선 네트워크 I/O가 시스템 병목의 대부분을 차지하기 때문에, 메시지를 압축해 전송함으로서 전송량을 줄이고 처리량을 극대화 할 수 있어서 압축 전송 기능을 지원합니다.
지원하는 압축 타입은 아래와 같습니다.
- gzip
- snappy
- lz4
- zstd
압축 타입에 따라 특성이 조금씩 다른데,
- 일반적으로 높은 압축률이 필요한 경우라면, gzip이나 zstd를 권장
- 빠른 응답 속도가 필요하다면 lz4나 snappy를 권장
토픽, 파티션, 오프셋
이전 글에서 토픽과 파티션에 대해 설명을 해놓은 적이 있었는데,
간단하게 다시 설명하자면
- 프로듀서가 메세지를 보내면 브로커가 받고
- 해당 메세지를 토픽이라는 곳에 저장
- 토픽에 쌓인 메시지를 병렬 처리 하기 위해 토픽을 여러 개의 파티션 단위로 나눈 곳에 메세지 저장
카프카에서는 위와 같이 파티셔닝을 통해 하나의 토픽이라도 높은 처리량을 수행할 수 있도록 해줍니다.
여기서 오프셋 이라는 단어가 등장합니다.
오프셋이란?
토픽안에 여러 파티션으로 파티셔닝을 하면 각 파티션에 메시지가 저장이 되는데,
이 때 메시지가 저장되는 위치를 오프셋 이라고 합니다.
오프셋은 순차적으로 증가하는 숫자(64비트 정수) 형태로 되어있습니다.
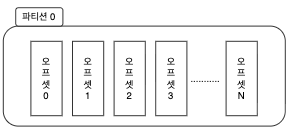
그림에서 보는 것 처럼 파티션에 순차적으로 숫자가 증가하는 데, 이 숫자들이 바로 오프셋 입니다.
각 파티션에서 오프셋은 고유한 숫자로 카프카에서는 오프셋을 통해 메시지의 순서를 보장하고 컨슈머에서는 마지막에 읽은 위치를 알 수 있습니다.
고가용성 보장
맨 처음에 말한 것 처럼 카프카는 분산 시스템이기 때문에, 하나의 서버나 노드가 다운되어도 다른 서버 또는 노드가 대신해서 처리가 가능합니다.
이러한 고가용성을 보장하기 위해 카프카에서는 리플리케이션 기능을 제공합니다.
이것도 마찬가지로 이전 글에서 리플리케이션에 대한 설명을 했는데,
간단하게 설명을 하자면,
리플리케이션 팩터의 숫자를 정해주면, 토픽의 파티션 마다 리더 브로커, 팔로워 브로커의 개수를 정할 수 있습니다.
예를 들어
- 브로커의 개수가 3개라고 하고,
- 리플리케이션 팩터를 2로 지정을 하면
| 파티션 | 리더 브로커 | 팔로워 브로커 |
|---|---|---|
| partition-0 | broker-1 | broker-2 |
| partition-1 | broker-2 | broker-3 |
| partition-2 | broker-3 | broker-1 |
위 표에서 본 것 처럼 각 파티션 별로 리더 1개, 팔로워 1개 브로커가 할당이 됩니다.
만약 리플리케이션 팩터를 3으로 지정을 하면, 리더 1개, 팔로워 2개 이렇게 브로커가 할당이 됩니다.
리더는 프로듀서, 컨슈머로부터 오는 모든 읽기, 쓰기 요청을 처리하며
팔로워는 오직 리더로부터 리플리케이션하게 됩니다.
이렇게 카프카는 고가용성을 구성 합니다.
일반적으로 운영 환경에서 카프카를 사용하면 리플리케이션 팩터 수를 3으로 구성하는 것을 권장 합니다.
주키퍼의 의존성
카프카를 공부하다보면 꼭 나오는 주키퍼 (zookeeper) 입니다.
주키퍼란?
지노드 _(znode)_를 이용해 카프카의 메타 정보를 주키퍼에 기록하고, 주키퍼는 이러한 지노드를 이용해 브로커의 노드 관리, 토픽 관리, 컨트롤러 관리 등 매우 중요한 역할을 합니다.
다만, 최근 주키퍼 성능의 한계가 생기기 시작하여 최신 버전의 카프카를 설치하다보면 주키퍼 버전이 아닌 KRaft 버전으로 설치를 많이 하고 있습니다.
현재는 주키퍼는 카프카의 중요한 메타데이터를 저장하고 각 브로커를 관리하는 중요한 역할을 한다 라고만 알고 있으면 될 것 같습니다.
이상 입니다.
'Kafka' 카테고리의 다른 글
| Kafka 리플리케이션 완벽 이해: 동작 원리부터 토픽 설정까지 (0) | 2025.10.31 |
|---|---|
| 카프카 프로듀서 구조와 동작 원리 (0) | 2025.10.24 |
| Kafka 저장 구조의 모든 것: Partition, Replication, Segment (0) | 2025.10.24 |
| Strimzi Kafka 설치 (1) | 2025.08.13 |
| Strimzi kafka 란? (2) | 2025.08.11 |