CDC 사용하는 이유
CDC는 Change Data Capture 의 약자 입니다.
서비스를 운영하다 보면 DB의 변경사항을 다른 시스템에 전파해야 하는 상황이 생깁니다. 흔히 애플리케이션 코드에서 직접 이벤트를 발행하는 방식을 쓰지만, 이 경우 DB 저장과 이벤트 발행이 동시에 성공해야 한다는 부담이 있습니다.
이 문제를 해결하는 방법 중 하나가 CDC(Change Data Capture) 입니다. DB에 직접 쓰기만 하면 변경사항이 자동으로 이벤트로 발행되기 때문에, 애플리케이션 코드를 건드릴 필요가 없습니다.
이번 글에서는 Kubernetes 환경에서 Strimzi Kafka와 Debezium을 사용해 MySQL의 변경사항을 실시간으로 Kafka 토픽으로 스트리밍하는 방법을 정리해보겠습니다.
사전 준비
- k8s
- Strimzi Kafka 설치
- MySQL 설치
아키텍처
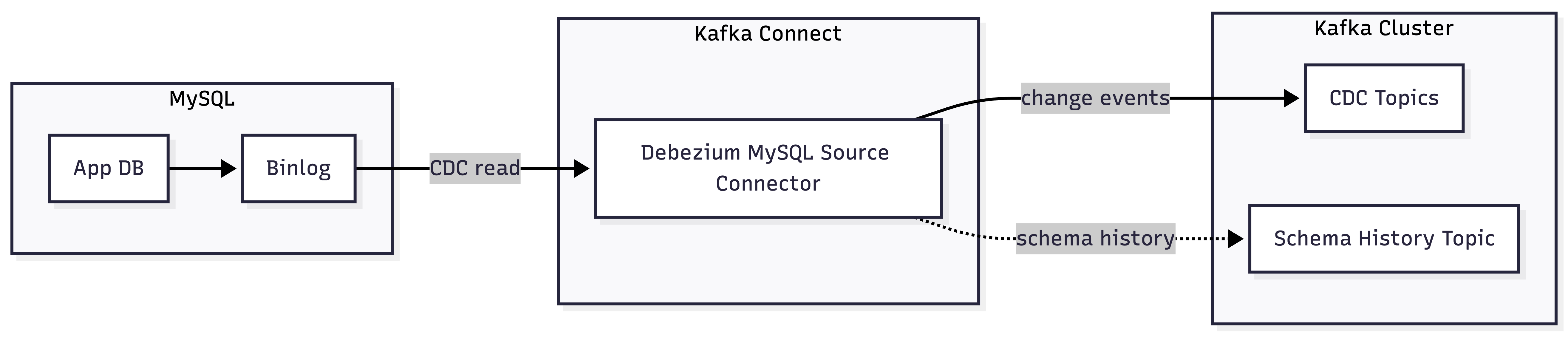
MySQL
- App DB: 애플리케이션이 실제로 읽고/쓰는 데이터베이스입니다.
- Binlog: MySQL에서 발생한 INSERT / UPDATE / DELETE 같은 변경 내역이 기록되는 로그입니다.
- Debezium은 테이블을 직접 계속 조회(polling)하는 게 아니라, 이 Binlog를 읽어서 변경 이벤트를 감지합니다.
Kafka Connect
- Debezium MySQL Source Connector가 동작하는 런타임입니다.
- 역할은 MySQL Binlog를 읽고 -> Kafka 메시지 이벤트로 변환 -> Kafka Cluster로 전송하는 것입니다.
- 즉, MySQL과 Kafka 사이의 브리지(중간 연결 계층)입니다.
Kafka Cluster
- CDC Topics: 실제 변경 이벤트가 쌓이는 Kafka 토픽들입니다.
ex) 예: 주문 테이블 변경 이벤트, 고객 테이블 변경 이벤트 - Schema History Topic: Debezium이 스키마 변경 이력(컬럼 구조 변경 등)을 관리하기 위한 내부 토픽입니다.
- 운영 시 디버깅/복구에 중요하지만, 일반 소비자 서비스가 직접 소비하는 토픽은 보통 아닙니다.
데이터 흐름
- App DB -> Binlog: 애플리케이션 트랜잭션 발생
- Binlog -> Kafka Connect: Debezium Connector가 변경 로그 읽음 (CDC read)
- Kafka Connect -> CDC Topics: 변경 이벤트를 Kafka 토픽으로 발행 (change events)
- Kafka Connect -> Schema History Topic: 스키마 이력 저장 (schema history)
핵심 요약:
- MySQL 변경사항을 Binlog 기반으로 감지
- Kafka Connect(Debezium)가 이벤트로 변환
- Kafka Cluster 토픽으로 전달
- 이후 소비자(Consumer)가 Kafka 토픽을 구독해서 후속 처리합니다.
이제 Kafka <-> MySQL 연결을 해보도록 하겠습니다.
MySQL 설정 변경
1. Binary Log 설정 추가
저 같은 경우는 MySQL 설치를 bitnamilegacy Helm 차트를 사용해서 설치를 했다보니, values.yaml 내용을 수정하였습니다.
primary.configuration의 [mysqld] 섹션에 아래 내용 추가
primary:
configuration: |-
[mysqld]
# ... 기존 설정 ...
# Kafka Debezium CDC 설정
server-id=1 # Debezium이 MySQL에 Replica 처럼 등록될 때 서버를 식별하는 고유 ID. 해당 ID가 없으면 Debezium이 연결 자체를 못함
log-bin=mysql-bin # Binlog 활성화, 기본적으로 꺼져있을 수 있으며 이게 없으면 읽을 로그가 없음
binlog_format=ROW # Binlog를 행(Row) 단위로 기록 "ROW" 모드여야 행의 before/after 값을 정확히 알 수 있음
binlog_row_image=FULL # 변경된 행의 모든 컬럼 값을 로그에 기록
binlog_expire_logs_seconds=604800 # binlog 저장 기간 7일 (MySQL 8.x 이상, expire_logs_days 대신)
gtid_mode=ON # 각 트랜잭션에 전역 고유 ID 부여, Debezium 재시작 후 정확히 "어디서부터" 이어 읽을 지 위치 추적에 필요
enforce_gtid_consistency=ON # GTID 모드를 켯을 때, GTID와 호환되지 않는 트랜잭션을 거부, GTID 무결성 보장용위 설정을 추가한 이유
먼저 Debezium이 동작하는 방식을 먼저 이해해야 합니다.
Debezium은 MySQL의 "복제 슬레이브(Replica)" 처럼 동작 합니다.
MySQL Master -> Slave 복제할 때 사용하는 Binlog(바이너리 로그) 를 직접 읽어서 변경사항을 Kafka로 보냅니다.
MySQL (binlog 생성) → Debezium (binlog 읽기) → Kafka Topic2. Debezium 전용 사용자 권한 부여 (MySQL 접속 후 실행)
-- Debezium 전용 사용자 생성
CREATE USER 'debezium'@'%' IDENTIFIED BY 'debezium_password';
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium'@'%';
FLUSH PRIVILEGES;설정이 필요한 이유
| 권한 | 이유 |
|---|---|
| REPLICATION SLAVE | Debezium이 Binlog를 직접 스트리밍받는 핵심 권한. Replica 서버가 Master의 binlog를 받는 것과 동일한 권한 |
| REPLICATION CLIENT | SHOW MASTER STATUS, SHOW SLAVE STATUS 등 복제 상태 조회 권한. Debezium이 현재 binlog 위치를 확인하는 데 필요 |
| SELECT | 커넥터 처음 시작 시 스냅샷(초기 전체 데이터 복사) 를 위해 테이블을 읽는 데 필요 |
| RELOAD | FLUSH TABLES WITH READ LOCK 실행 권한. 스냅샷 시 데이터 일관성을 위해 잠깐 테이블을 잠그는 용도 |
| SHOW DATABASES | 어떤 DB/테이블을 모니터링할지 목록을 확인하는 데 필요 |
3. DB 테이블에 PK 확인
Debezium은 기본적으로 PK가 없는 테이블은 캡처 불가 합니다.
설정이 필요한 이유
Debezium은 Kafka 토픽에 메시지를 보낼 때 Kafka Message Key = MySQL PK 값으로 매핑합니다.
MySQL Row (id=5, name="홍길동")
→ Kafka Message { key: "5", value: { before: {...}, after: {...} } }
PK가 없으면:
- Kafka에서 어떤 행이 변경됐는지 식별 불가
- 같은 행에 대한 UPDATE/DELETE 이벤트가 다른 파티션에 분산되어 순서 보장 불가
- Debezium이 기본 설정에서 해당 테이블을 아예 캡처 거부
Kafka Connect 설치
Strimzi의 KafkaConnect는 기본 이미지에 Debezium 플러그인이 포함되어 있지 않습니다.
KafkaConnect는 플러그인을 통해 다양한 외부 시스템과 연결할 수 있는데, 어떤 플러그인을 사용할지는 사용자가 직접 이미지에 포함시켜야 합니다.
즉, "Debezium MySQL 플러그인이 포함된 KafkaConnect 이미지" 를 직접 빌드해서 사용해야 합니다.
Debezium 플러그인 다운로드
이미지 빌드하기 위해선, 아래 정보들을 먼저 확인해야 합니다.
- strimzi operator 버전
- Kafka 버전
- Kafka 버전과 호환되는 Debezium 플러그인 버전
아래 링크에서 Release 버전 별로, 자신이 사용하고 있는 Kafka 버전에 맞춰 Plugin 다운로드를 하면 됩니다.
Debezium Release Note 링크
다운로드는 아래 링크에서 해주면 됩니다.
Debezium 다운로드 링크
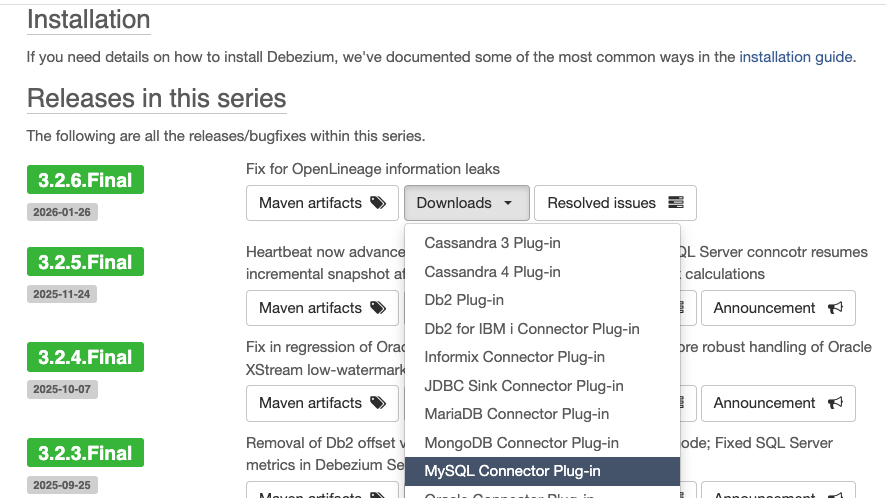
저 같은 경우 Kafka 4.0.0 버전을 사용하고 있어서 3.2.6.Final 버전의 플러그인을 다운 받았습니다.
Kafka Connect 이미지 빌드
이제 플러그인을 넣어서 Kafka Connect 이미지 빌드를 해보겠습니다.
이미지 빌드하는 방법은 아래 공식문서를 참조하였습니다.
Strimzi Kafka 공식문서
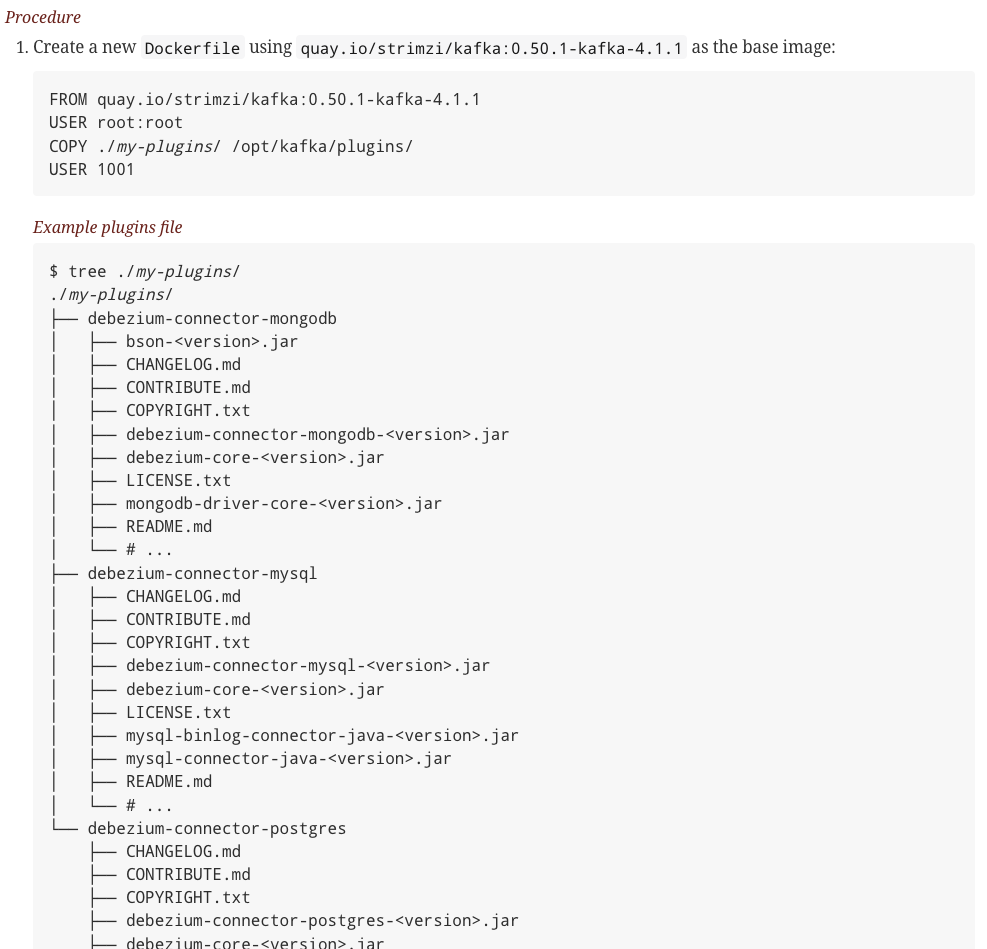
여기서 베이스 이미지는 현재 사용하고 계신 Operator, Kafka 버전을 넣어주시면 됩니다.
quay.io/strimzi.kafka:<자신이 사용하는 Operator Version>-kafka-<자신이 사용하는 Kafka Version>
- 예시
FROM quay.io/strimzi/kafka:0.47.0-kafka-4.0.0
USER root:root
COPY ./my-plugins/ /opt/kafka/plugins/
USER 1001
저는 이대로 빌드하여 ECR에 Push 하여 사용하였습니다.
이제 KafkaConnect 리소스 생성을 해보겠습니다.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: kafka-connect
namespace: <원하는 네임스페이스>
annotations:
strimzi.io/use-connector-resources: "true"
spec:
version: <사용하고 있는 Kafka Cluster 버전>
image: <앞서 빌드한 이미지>
replicas: 1
bootstrapServers: <설치한 Strimzi Kafka 서비스 주소>
tls:
trustedCertificates: # Kafka Connect가 브로커의 인증서가 진짜인지 검증
- secretName: kafka-cluster-cluster-ca-cert
pattern: "*.crt"
authentication: # Kafka Connect가 브로커에게 자기 자신을 검증 할 때 사용하는 인증서
type: tls
certificateAndKey:
secretName: <kafka cert가 있는 secret 이름>
certificate: user.crt
key: user.key
config: # Kafka Connect는 자신의 상태를 관리하기 위해 Kafka에 내부 토픽 생성
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1
spec.config 에서 정의한 내용에 대해 설명을 하자면, KafkaConnect 내부 토픽 설정입니다.
KafkaConnect는 자신의 상태를 관리하기 위해 Kafka에 내부 토픽 3개를 자동으로 생성합니다.
| 설정 | 토픽명 | 저장 내용 |
|---|---|---|
| offset.storage.topic | connect-cluster-offsets | 각 Connector가 MySQL binlog 어디까지 읽었는지 위치 저장 |
| config.storage.topic | connect-cluster-configs | Connector 설정 정보 저장 |
| status.storage.topic | connect-cluster-status | Connector/Task 상태 저장 (RUNNING, FAILED 등) |
group.id:
- KafkaConnect 워커가 있을 때 같은 클러스터로 묶어주는 식별자
- group.id를 가진 워커들이 하나의 Connect 클러스터를 구성합니다
replication.factor: -1 의미 :
- 브로커의 default.replication.factor 설정을 따라간다는 뜻
- 현재 kafka-persistent.yaml:143 에 default.replication.factor: 2 로 설정되어 있으므로 이 토픽들도 2로 복제됩니다
Kafka Connector 리소스 생성
이제 Kafka Connect 리소스가 정상적으로 생성이 되었다면,
MySQL과 연결하기 위해 KafkaConnector 리소스를 생성해보도록 하겠습니다.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: mysql-cdc-source
namespace: <앞서 생성한 KafkaConnect 리소스와 같은 네임스페이스>
labels:
strimzi.io/cluster: <앞서 생성한 KafkaConnect 리소스 이름>
spec:
class: io.debezium.connector.mysql.MySqlConnector
tasksMax: 1
config:
database.hostname: <mysql 주소>
database.port: <mysql 포트>
database.user: <mysql 사용자 이름>
database.password: <mysql 사용자 비밀번호>
database.server.id: "<MySQL에 연결된 다른 슬레이브/Debezium 인스턴스 ID와 겹치지 않는 숫자>"
topic.prefix: mysql1
database.include.list: appdb
table.include.list: appdb.orders,appdb.customers
schema.history.internal.kafka.bootstrap.servers: <설치한 Kafka Service 주소>
schema.history.internal.kafka.topic: schema-history.mysql1
snapshot.mode: initial
provide.transaction.metadata: "true"Kafka Connector가 하는 일
- MySQL binlog를 읽음
- MySQL에 직접 쿼리하는 게 아니라, binlog(DB 변경 로그)를 실시간으로 구독
INSERT/UPDATE/DELETE이벤트 감지
- 읽고싶은 DB와 테이블 지정
database.include.list: appdb기준으로 변경 사항을 Kafka에 주고 싶은 데이터베이스 지정table.include.list: appdb.orders,appdb.customers기준으로 변경 사항을 kafka에 주고 싶은 table 지정
- 변경 이벤트를 Kafka Topic으로 발행
topic.prefix: mysql1기준으로 자동으로 토픽 생성mysql1.appdb.orders,mysql1.appdb.customers이런 형태로 만들어짐
- 스냅샷 (첫 실행 시)
snapshot.mode: initial이므로 처음 실행할 때, 현재 테이블 데이터를 전부 읽어서 Kafka에 밀어넣고, 그 이후부터 binlog 변경분만 추적
한줄 요약
MySQL 데이터 변경 사항을 실시간으로 Kafka 메시지로 변환해주는 역할
결과 확인
MySQL에서 appdb 데이터베이스 생성하고, orders, customers 테이블을 생성을 해준 후 데이터 INSERT
-- 1. 데이터베이스 생성
CREATE DATABASE IF NOT EXISTS appdb
CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
USE appdb;
-- 2. 테이블 생성
CREATE TABLE customers (
id BIGINT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
email VARCHAR(255),
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);
CREATE TABLE orders (
id BIGINT NOT NULL AUTO_INCREMENT,
customer_id BIGINT NOT NULL,
status VARCHAR(50),
total_amount DECIMAL(10, 2),
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);
-- 3. 트랜잭션으로 데이터 INSERT
START TRANSACTION;
INSERT INTO customers (name, email) VALUES
('홍길동', 'hong@example.com'),
('김철수', 'kim@example.com'),
('이영희', 'lee@example.com');
INSERT INTO orders (customer_id, status, total_amount) VALUES
(1, 'pending', 15000.00),
(1, 'completed', 32000.00),
(2, 'pending', 8500.00);
-- 트랜잭션 ID 확인
SELECT TRX_ID FROM information_schema.INNODB_TRX WHERE TRX_MYSQL_THREAD_ID = CONNECTION_ID();
COMMIT;
그리고 kafka 토픽에서 메시지를 확인하면 아래와 같이 결과가 나오는 것을 확인할 수 있습니다.
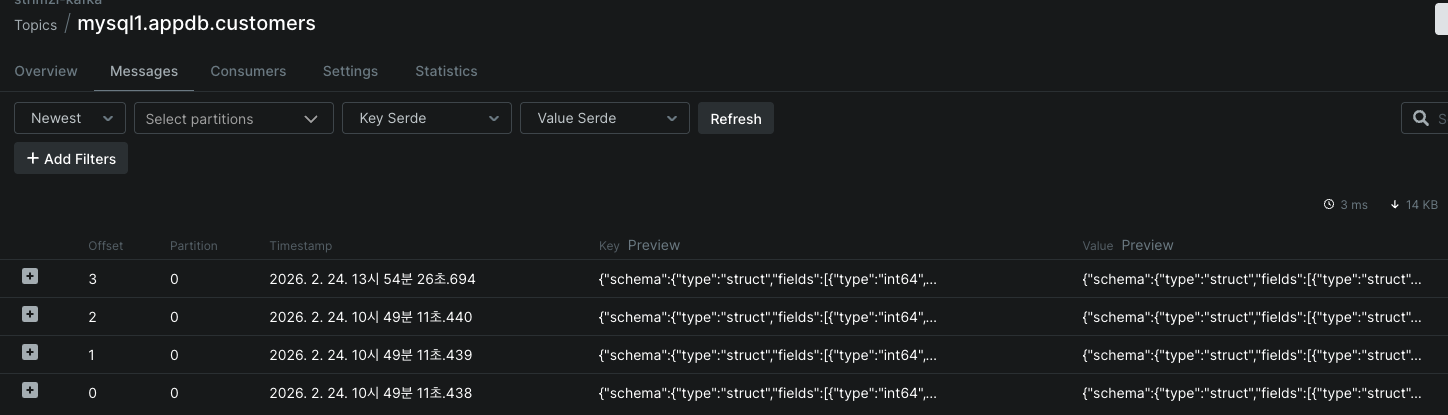

이상 입니다.
'Kafka' 카테고리의 다른 글
| Kafka Schema Registry 구축 - EKS에 Apicurio Registry 설치하기 (0) | 2026.02.27 |
|---|---|
| Kafka 스키마 레지스트리란 무엇인가? (0) | 2026.02.26 |
| Strimzi Kafka 모니터링 구축 가이드: Prometheus + Grafana로 메트릭 수집하기 (1) | 2025.12.11 |
| Strimzi Kafka mTLS 적용 알아보기 (0) | 2025.12.03 |
| AWS MSK 메트릭 수집 및 모니터링 (0) | 2025.11.06 |