스키마(Schema) 란?
데이터의 구조(형식)를 정의한 설계도
즉,
- 어떤 필드가 있는지
- 각 필드의 타입이 무엇인지
- 필수인지 선택인지
- 기본값은 무엇인지
를 정의한 문서
Kafka 스키마 레지스트리(Schema Registry) 란?
Kafka는 원래 메시지 바이트 배열 만 저장/전달 합니다.
즉, Kafka 자체는 “이 데이터가 어떤 구조인지(필드/타입)”을 모릅니다.
그래서 스키마 레지스트리는 Kafka 메시지의 데이터 구조(스키마)를 중앙에서:
- 저장(버전 관리)
- 호환성 검사(Compatibility)
- 조회(역 직렬화에 사용)
해주는 메타 데이터 서버 입니다.
핵심: 데이터는 Kafka에 저장되고, 스키마는 Registry에 저장
사용 이유
- 스키마 변경으로 인한 장애를 막기 위해
예를 들어) Producer가 갑자기 필드 타입을 바꾸거나 삭제를 하는 경우
레지스트리를 사용하면 “허용되는 변경만” 통과 시키고,
위험한 변경은 등록 단계에서 차단할 수 있음
- 멀티팀/멀티서비스에서 스키마 구조를 강제하기 위해
Topic을 여러 팀이 공유하면, 메시지 포맷이 문서만으로는 절대 안정적으로 유지되지 않기에
스키마 레지스트리를 두어 실제 실행 경로에서 스키마 구조를 강제하기 합니다.
동작 흐름
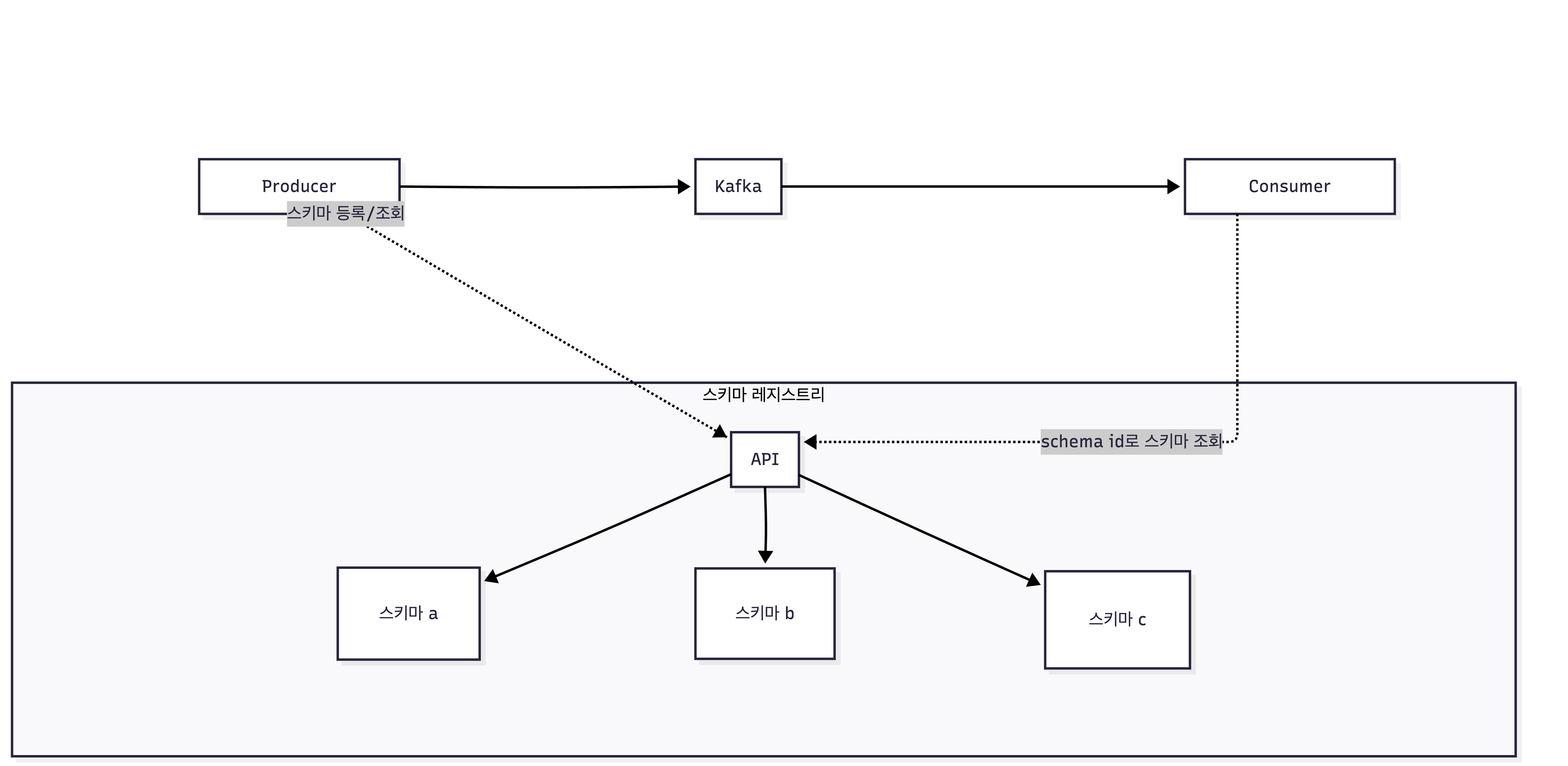
- Producer 쪽
- 스키마를 레지스트리에 등록, 또는 이미 등록된 스키마 ID 조회 진행
- 메시지를 직렬화 할 때, schema id를 헤더처럼 같이 붙여서 Kafka로 전송
- Consumer 쪽
- Kafka에서 메시지를 받으면 schema id를 확인
- 레지스트리에서 그 schema id에 해당하는 스키마를 받아서 역직렬화
여기서 호환성을 지키기 위해 아래와 같은 전략을 사용합니다.
- BACKWARD: 새 Consumer가 옛날 데이터를 읽을 수 있게
- FORWARD: 옛 Consumer가 새 데이터를 읽을 수 있게
- FULL: 양방향 호환
실무에선 보통 BACKWARD로 두고 스키마 변경룰을 팀 규칙으로 정합니다.
스키마 변경을 할 때 사용하는 안전 규칙
스키마는 한 번 배포되면 여러 Producer/Consumer가 함께 사용하므로, 변경할 때는 호환성(Compatibility) 기준을 반드시 지켜야 합니다.
여기서는 실무에서 가장 많이 사용하는 BACKWARD 호환성 기준으로 정리합니다.
일반적으로 안전한 변경 (BACKWARD 호환 기준)
- 필드 추가
- 기존 Consumer가 해당 필드를 몰라도 동작할 수 있도록 설계하면 안전합니다.
- optional 필드 추가
- 새 필드가 없어도 기존 데이터 해석이 가능하므로 비교적 안전합니다.
- 기본값(default)이 있는 필드 추가
- 이전 메시지에 해당 필드가 없어도 기본값으로 처리할 수 있습니다.
- enum 값 추가 (주의 필요)
- Consumer 구현이 새 enum 값을 처리할 수 있는지 확인해야 합니다.
위험한 변경 (호환성 깨질 가능성이 큼)
- 필드 삭제
- 기존 Consumer가 기대하는 필드가 사라져 역직렬화/로직 처리에 문제가 생길 수 있습니다.
- 필드 타입 변경
- 예:
int -> string - 대부분의 경우 기존 Consumer와 호환되지 않습니다.
- 예:
- 필드 이름 변경(리네이밍)
- 단순 이름 변경처럼 보여도, 실제로는 기존 Consumer 입장에서 다른 필드로 인식될 수 있습니다.
- 필드 의미 변경
- 타입은 같아도 의미가 바뀌면(예:
price단위 변경) 운영 장애로 이어질 수 있습니다.
- 타입은 같아도 의미가 바뀌면(예:
실무 팁
- 스키마 변경은 “기술적으로 등록 가능하냐”보다 기존 Consumer가 안전하게 읽을 수 있느냐를 기준으로 판단해야 합니다.
- 실무에서는 보통 호환성 모드를 BACKWARD로 두고, 팀 규칙으로 다음을 함께 관리합니다.
- 필드 추가 시
optional/default사용 - 삭제/타입 변경은 새 버전 토픽 또는 충분한 마이그레이션 전략과 함께 진행
- 필드 추가 시
마무리
Kafka는 메시지를 잘 전달하는 데 강하지만, 메시지의 구조(스키마) 자체를 이해하지는 못합니다.
그래서 실제 운영 환경에서는 스키마 레지스트리를 통해 스키마 버전 관리, 호환성 검사, 안전한 변경 통제를 함께 가져가는 것이 중요합니다.
정리하면:
- 데이터(payload)는 Kafka에 저장
- 스키마는 Schema Registry에 저장
- Producer/Consumer는 스키마 ID를 기준으로 직렬화/역직렬화를 수행
- 스키마 변경은 호환성 규칙(BACKWARD/FORWARD/FULL) 아래에서 관리
다음 글에서는 실제로 스키마 레지스트리(Apicurio Registry)를 설치하고, 어떻게 동작이 되는지 알아보겠습니다.
감사합니다.
'Kafka' 카테고리의 다른 글
| Kafka Schema Registry 구축 - EKS에 Apicurio Registry 설치하기 (0) | 2026.02.27 |
|---|---|
| Strimzi Kafka + Debezium으로 MySQL CDC 구축하기 (0) | 2026.02.24 |
| Strimzi Kafka 모니터링 구축 가이드: Prometheus + Grafana로 메트릭 수집하기 (1) | 2025.12.11 |
| Strimzi Kafka mTLS 적용 알아보기 (0) | 2025.12.03 |
| AWS MSK 메트릭 수집 및 모니터링 (0) | 2025.11.06 |