반응형
Apache Kafka 란?
Apache Kafka는 고성능의 분산 메시징 시스템으로, 대규모의 데이터를 실시간으로 처리하고 전달하는 데 최적화된 플랫폼 입니다.
흔히 실시간 로그 수집, 이벤트 스트리밍, 데이터 파이프라인 구성 등에 사용됩니다.
Kafka 구성
Kafka는 고성능 TCP 네트워크 프로토콜을 통해 통신하는 서버 와 클라이언트 로 구성된 분산 시스템입니다.
서버 :
- Kafka는 하나 이상의 서버로 구성된 클러스터로 실행됩니다.
- 서버 중 일부는 브로커라고 하는 스토리지 계층을 구성합니다.
- 다른 서버는 Kafka Connect를 실행하여 이벤트 스트림으로 데이터를 지속적으로 가져오고 내보내 Kafka를 관계형 데이터베이스 및 다른 Kafka 클러스터와 같은 기존 시스템과 통합합니다.
- Kafka 클러스터는 높은 확장성과 내결함성을 제공합니다. 서버에 장애가 발생하더라도 다른 서버가 해당 작업을 인계받아 데이터 손실 없이 지속적인 운영을 보장합니다.
클라이언트 :
- 네트워크를 통해 브로커(서버)와 통신 합니다.
- 이벤트 스트림을 생성(Produce)*, 읽기(Consume), 처리(Process) 하는 역할.
Kafka 기본 구조
- Producer(프로듀서): 데이터를 생성해서 카프카로 보내는 역할(예: 로그, 트랜잭션 데이터 등).
- Broker(브로커): 카프카 서버, 데이터를 저장하고 관리(여러 대로 클러스터 구성).
- Topic(토픽): 데이터가 저장되는 논리적 구분(예: “order-log”, “user-activity” 등).
- Partition(파티션): 토픽을 여러 개의 물리적 저장 단위로 나눔(확장성과 병렬성↑).
- Consumer(컨슈머): 데이터를 읽어가는 역할(데이터 소비, 분석 등).
- Consumer Group(컨슈머 그룹): 여러 컨슈머가 협력해 데이터를 나눠서 읽음.
구조를 보면 아래 그림과 같습니다.
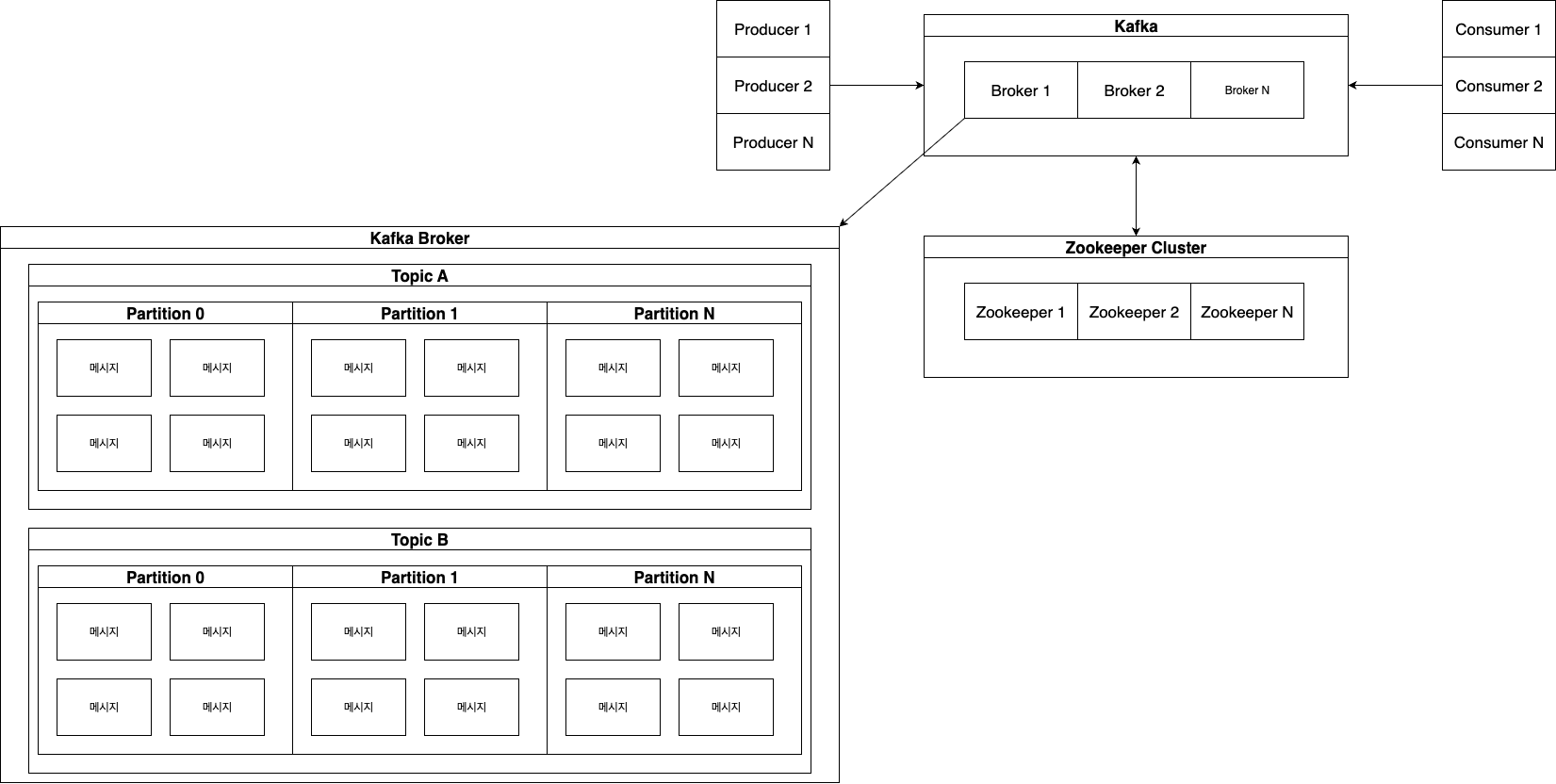
동작 방식에 대해 간단히 정리를 하자면, 아래와 같습니다.
- Producer가 데이터를 생성해 Kafka Broker의 특정 Topic으로 전송
- Broker 서버로 전송된 메시지는 Topic의 Partition에 저장
- Consumer는 Topic/Partition에서 메시지를 가져 갑니다.
- Zookeeper는 클러스터의 메타데이터 관리, Broker/Partition 상태 감시, 리더 Broker 선출 등 관리 역할을 합니다.
✅ Kafka 핵심 요약
- Apache Kafka는 대용량 데이터를 빠르고 안정적으로 실시간 처리할 수 있는 분산 메시징 플랫폼입니다.
- Producer가 데이터를 보내면, Kafka는 Broker를 통해 데이터를 Topic의 여러 Partition에 분산 저장하고,
- Consumer는 필요한 데이터를 직접 읽어가는(Pull) 방식으로 동작합니다.
- Zookeeper(또는 최신 KRaft 모드)는 Kafka 클러스터의 메타데이터와 장애 복구, 리더 선출을 관리합니다.
- Kafka는 높은 확장성, 내결함성, 다양한 연동성을 바탕으로 실시간 데이터 파이프라인, 로그 수집, 이벤트 스트림 처리 등 다양한 분야에서 활용되고 있습니다.
반응형
'Kafka' 카테고리의 다른 글
| 카프카 프로듀서 구조와 동작 원리 (0) | 2025.10.24 |
|---|---|
| Kafka는 왜 이렇게 빠르고 안정적일까? — 높은 처리량과 안정성을 만드는 핵심 원리 (0) | 2025.10.24 |
| Kafka 저장 구조의 모든 것: Partition, Replication, Segment (0) | 2025.10.24 |
| Strimzi Kafka 설치 (1) | 2025.08.13 |
| Strimzi kafka 란? (2) | 2025.08.11 |