이번 회사에서 Kafka를 사용하게 되어서 알아보게 되었습니다.
Kafka 란?
Apache Kafka는 대규모 실시간 데이터 스트리밍 처리 시스템으로, LinkedIn에서 개발되어 현재는 Apache Software Foundation의 오픈소스로 관리되고 있습니다.
Kafka는 분산형 메시지 브로커 시스템으로, 실시간 로그 수집, 데이터 파이프라인, 스트리밍 분석 등 다양한 곳에서 사용됩니다.
Kafka를 사용하게 된 계기
문제 상황
- 현재 Chat 기반 문서 분석 Ai-Agent를 개발하고 있는데,
- Backend 서버에서 fetch를 통해 AI 분석 서버와 직접 통신
- 이 통신 구조에서 Backend의 힙 메모리 사용량이 기하급수적으로 증가하여 서버 사망
- fetch는 기본적으로 Promise 기반으로 비동기 요청이지만, Backend 레벨에서는 요청 완료까지 해당 Request/Response 오브젝트를 메모리에 유지해야 함
- 특히 분석 시간이 길다면, 요청 수가 많아질수록 미 처리된 요청이 누적되며 메모리를 점유
- AI 서버의 응답 지연 → 처리 대기 요청 증가 → Node.js (또는 JVM 등) 힙에 Event Loop backlog 또는 Pending Promise 객체가 누적
이에 따라 Kafka를 도입하게 되었습니다.
이제 Strimzi에 대해 알아보겠습니다.
Strimzi 란?
Strimzi는 Kubernetes 환경에서 Apache Kafka를 손쉽게 배포하고 운영할 수 있게 해주는 오픈소스 프로젝트입니다.
간단히 말하면, Kubernetes-native Kafka 운영 플랫폼입니다.
Strimzi의 장점
- 배포 자동화
- Helm, OperatorHub, YAML 등으로 손쉽게 Kafka 클러스터 생성 가능
- 운영 편의성
- 클러스터 상태 감시, 자동 롤링 업데이트, 인증/인가(ACL) 설정, TLS 자동 구성 등
- 확장성 및 안정성
- kubernetes의 Horizontal Pod Autoscaler, Persistent Volume 관리 등을 그대로 활용 가능
- CI/CD 통합 유리
- Kafka를 GitOps 기반으로 선언적으로 관리할 수 있음
💡 Strimzi는 이런 상황에서 유리함
- Kafka를 클라우드 네이티브 환경(Kubernetes)에서 운영하고자 할 때
- 수작업 없이 Kafka 인프라를 자동화하고 싶을 때
- Kafka Topic/User을 코드로 관리하고 싶을 때
- Kafka 운영을 DevOps 파이프라인에 통합하고 싶을 때
Strimzi의 구성요소
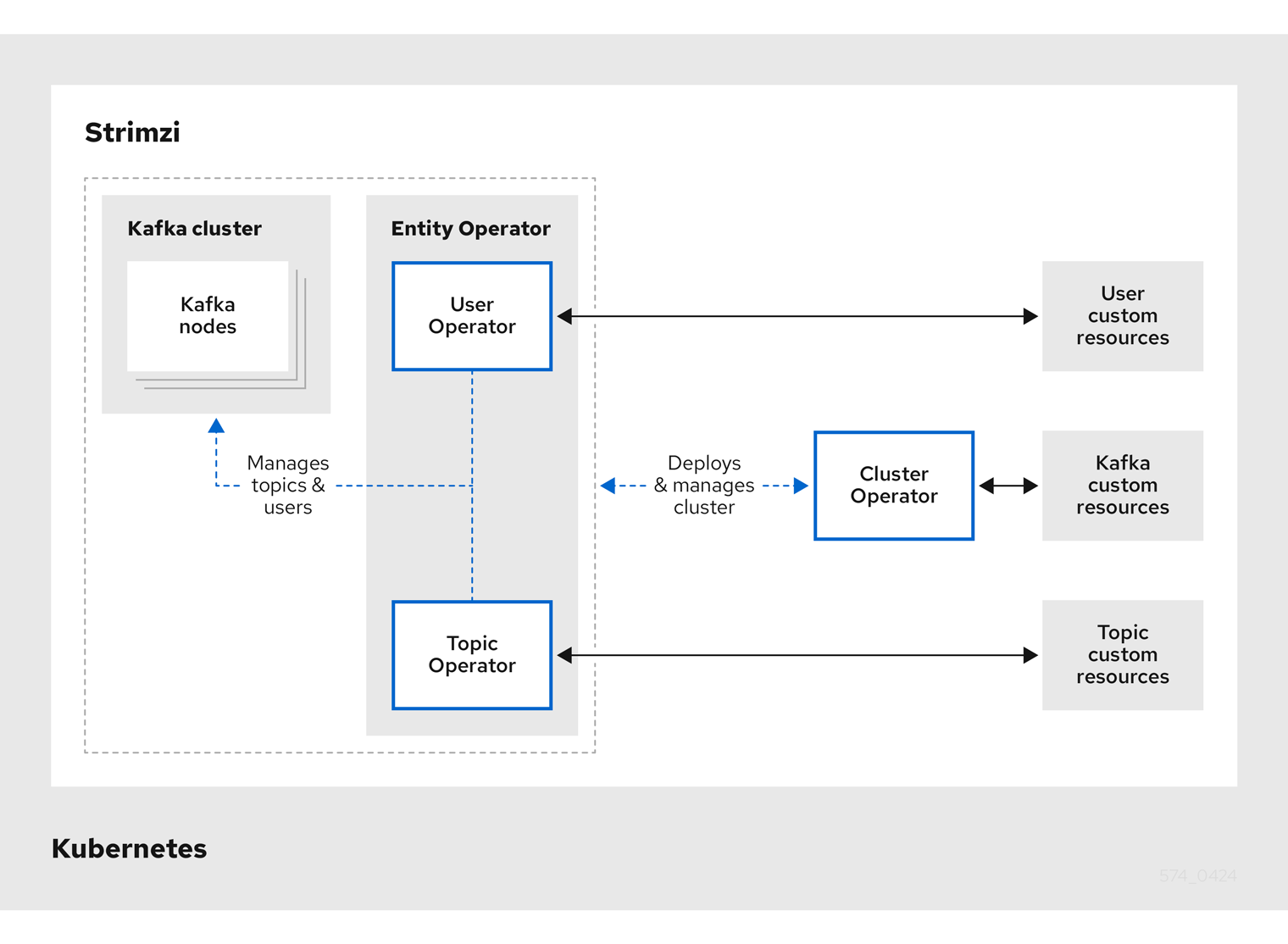
주요 구성 요소는 아래와 같습니다.
- Cluster Operator
- 역할: Kafka 클러스터 자체와 관련 리소스(Zookeeper, Kafka Broker 등)를 설치하고 관리.
- 동작: Kafka 관련 Custom Resource를 보고 클러스터를 구성함.
- Entity Operator 는 내부에 두 개의 Operator를 포함하고 있습니다.
- Topic Operator
- 역할: Kafka 토픽을 자동으로 생성, 설정 변경, 삭제.
- Kubernetes의 Topic Custom Resource를 보고 Kafka 내부의 토픽을 관리함.
- User Operator
- 역할: Kafka 사용자 생성, 인증 정보 관리 (예: SCRAM-SHA-512 사용자 비밀번호 등).
- Kubernetes의 User Custom Resource 기반으로 Kafka 사용자 계정 관리.
Cluster Operator
💡한 줄 요약:
Kafka 클러스터 전체를 설치하고 운영해주는 Kubernetes 안의 '감독관' 같은 역할 수행
좀 더 상세하게 알아보면, Cluster Operator는 아래 보이는 Kafka 구성 요소들을 설치하고 관리합니다.
- Kafka 브로커
- Kafka Exporter (메트릭 수집용)
- Cruise Control (리밸런싱 자동화)
- Kafka Connect (데이터 파이프라인용)
- Kafka MirrorMaker (다른 클러스터와 동기화)
- Kafka Bridge (Kafka <-> Http 통신)
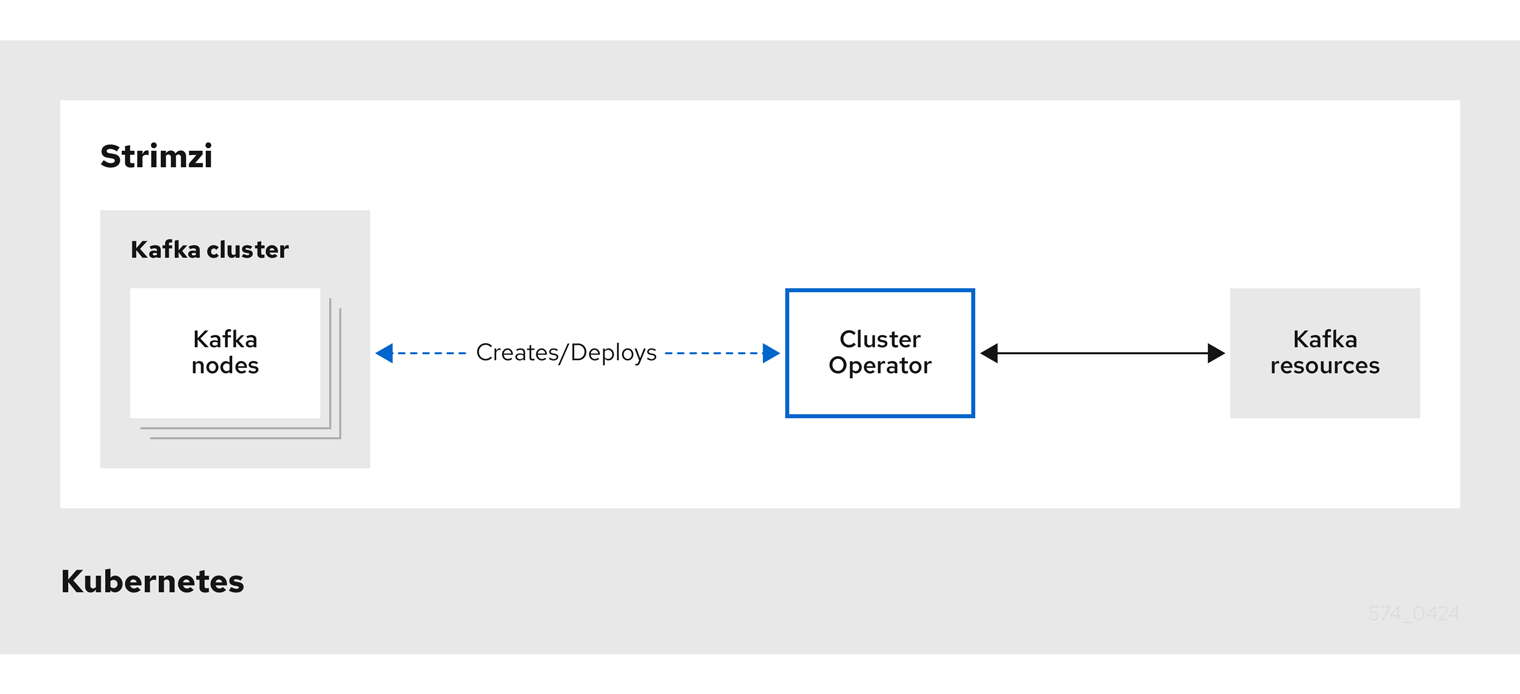
위 그림에서 보이는 것과 같이, Kubernetes에서 Kafka Cluster를 배포하기 위해서 사용자가 미리 정의해둔 Kafka resources를 보고 Cluster Operator가 설치를 해줍니다.
Topic Operator
Topic Operator는 앞서 설명했던 Cluster Operator에 의해 Kafka Cluster에 설치 됩니다.
Topic Operator는 Kafka의 Topic을 kubernetes 리소스로서 관리해주는 컴포넌트 입니다.
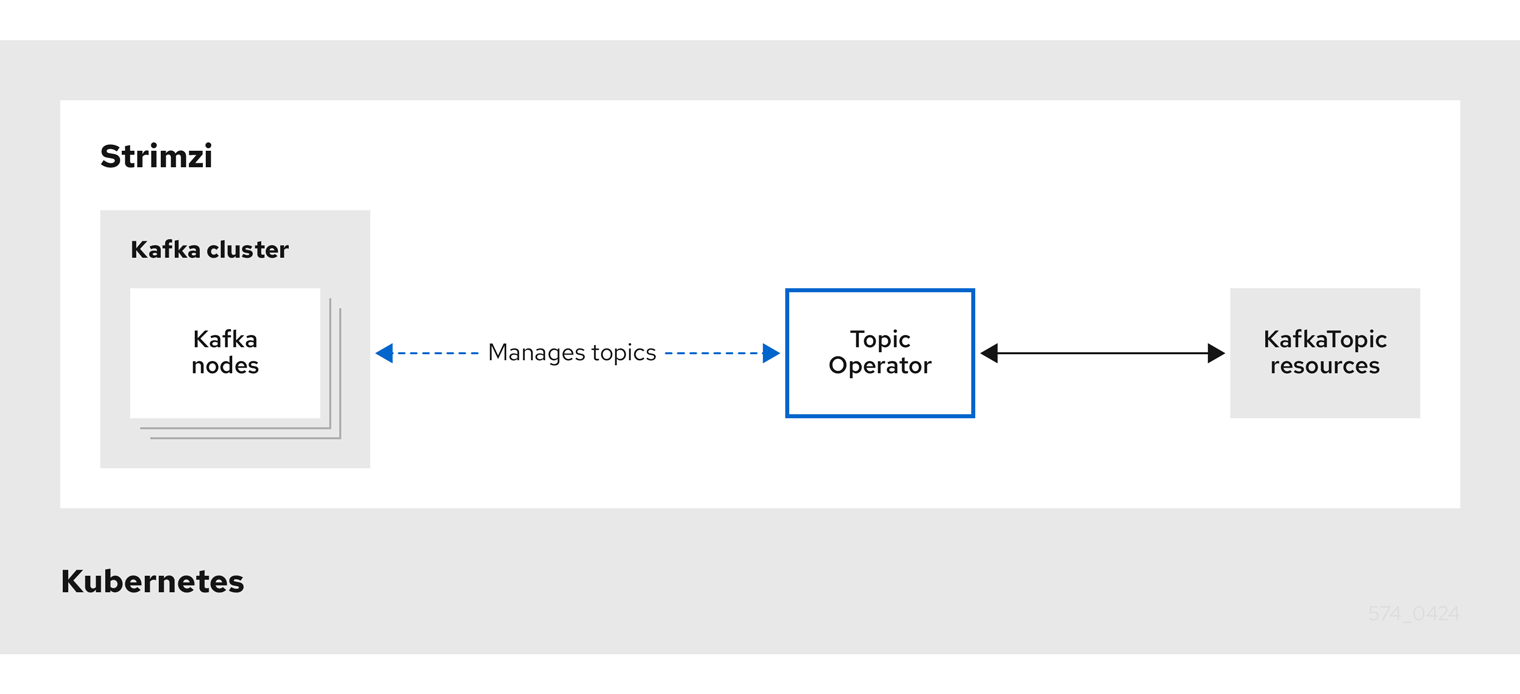
위 그림을 보면, Kubernetes에서 정의한 KafkaTopic resources와 실제 Kafka Cluster 내부에서 동작하는 Topic을 감시/관리 해줍니다.
User Operator
역할:
- kafkaUser CRD를 감시하고, 해당 리소스에 정의된 사용자를 Kafka 클러스터에 반영
- 인증 방식(SCRAM-SHA, TLS 등)과 인가(ACL) 설정 관리
- 사용자의 Quota(트래픽 제한, broker 리소스 사용량 제한 등) 설정 가능
- 사용자 Secret 자동 생성 및 업데이트
정리를 하자면, User Operator는 Producer든, Consumer든, Kafka에 접속하는 클라이언트의 "계정"을 만들어서 인증/권한을 관리할 때 사용합니다.
배포 방식
- Cluster Operator의 Entity Operator 구성 요소 중 하나로 함께 배포
Drain Cleaner
만약 쿠버네티스 노드에서 Drain이 일어나면 쿠버네티스 스케줄러는 그냥 파드를 강제로 다른 노드로 이동 시킵니다.
그러면 Kafka 브로커는 데이터 동기화 준비 없이 바로 내려가버리는 위험이 있습니다.
따라서 이를 방지하기 위해
- Drain Cleaner가 노드 드레인 시, 감지
- kafka 관련 파드에 annotation을 붙이고
- Kafka Cluster Operator가 해당 annotation을 보고 Rolling Update 절차를 진행 합니다.
- 리더 파티션 이동
- 데이터 복제 완료 대기
- 안전하게 파드 재시작
- 파드가 안전하게 다른 노드로 이동, under-replicated 상태 방지
정리하자면, Drain Cleaner는 Kafka 브로커 (POD)를 kubernetes 노드 드레인 시 안전하게 재배치 해주는 자동화 도구 입니다.
다음 글에서는 Strimzi kafka 배포 방법에 대해 알아보겠습니다.
'Kafka' 카테고리의 다른 글
| 카프카 프로듀서 구조와 동작 원리 (0) | 2025.10.24 |
|---|---|
| Kafka는 왜 이렇게 빠르고 안정적일까? — 높은 처리량과 안정성을 만드는 핵심 원리 (0) | 2025.10.24 |
| Kafka 저장 구조의 모든 것: Partition, Replication, Segment (0) | 2025.10.24 |
| Strimzi Kafka 설치 (1) | 2025.08.13 |
| Apache Kafka 에 대해 알아보기 (2) | 2025.08.06 |